您当前的位置: > 知识百科 >
什么是Aggregata?去中心化AI 数据资料市场
什么是Aggregata:去中心化AI 数据资料市场

Aggregata是一个去中心化的开源资料数据市场,用户可以创造高品质的资料数据并自行为期定价,透过Greendrive for Greenfield 直接上传到Aggregata 的去中心化资料库储存,而开发者可以付费调用这个资料库里面的已经预先处理好的现成内容,来简化或加速产品开发流程。
长远来看,Aggregata 试图打造的是Web 3 版本的Hugging Face。Hugging Face 是Web 2 一家知名的AI 公司,早期以聊天机器人起家,后期专注于自然语言处理(NLP)领域,最著名的产品是开源的NLP 模型库Transformers。
Transformers 当中收集了各种最新、最先进的预训练模型,可以用于文本分类、语言生成、机器翻译等多种NLP 任务,同时提供了一个简单易用的API,让开发者有相关需求的企业能够轻松地使用Transformers 的预训练模型进行各种NLP 任务,而不需要深入了解模型的细节,或从头训练调整自己的模型。
受惠于AI 的兴起,Hugging Face 成为GitHub 成为有史以来增长最快的AI 专案,现阶段的最新估值更已经超过45 亿美元。
增强资料数据自主权,实践DaaA 数据即产品(Data as an Asset)

数据和资料的提供者可以保留对其资料的完全所有权和控制权,灵活编辑分散储存的数据,将资料转化为一种资产,并且透过贡献资料和数据赚取代币,利用Web3 奖励模型最大限度地提高提供资料的获利能力。
快速存取数据,高效部署
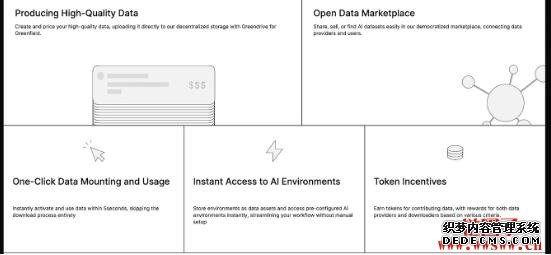
需要调用数据资料的开发者可在5 秒内立即启动并使用数据,这些资料集由非营利组织或大学维护,因此不必费心下载或花费大量时间解压缩,完全跳过冗长的数据取得过程,并可将环境储存为一种资料资产,在需要的时候立即存取预先配置的AI 环境,无需手动设定即可简化工作流程,同时在任何具有运算能力的伺服器上快速训练、微调推理和执行模型或建立知识库。
如何早期参与Aggregata

目前Aggregata 还处于相对早期的阶段,没有代币相关的讯息,也尚未开始正式经营Discord ,网站上开放下载的应用程式也还无法顺利使用(缺乏访问权限),建议密切关注官方X,等官方正式开放并提供教学说明后再进行下载,以策安全。